最近做个一基于SQL的无限级分类的目录模块,在网上看到了这个文章,非常不错.
原文是:https://www.cnblogs.com/analyzer/articles/847124.html
- 转载:https://sunzhy.blog.csdn.net/article/details/48660707
在看下面的无限级分类优化之前,请大家先看看原文先哈!
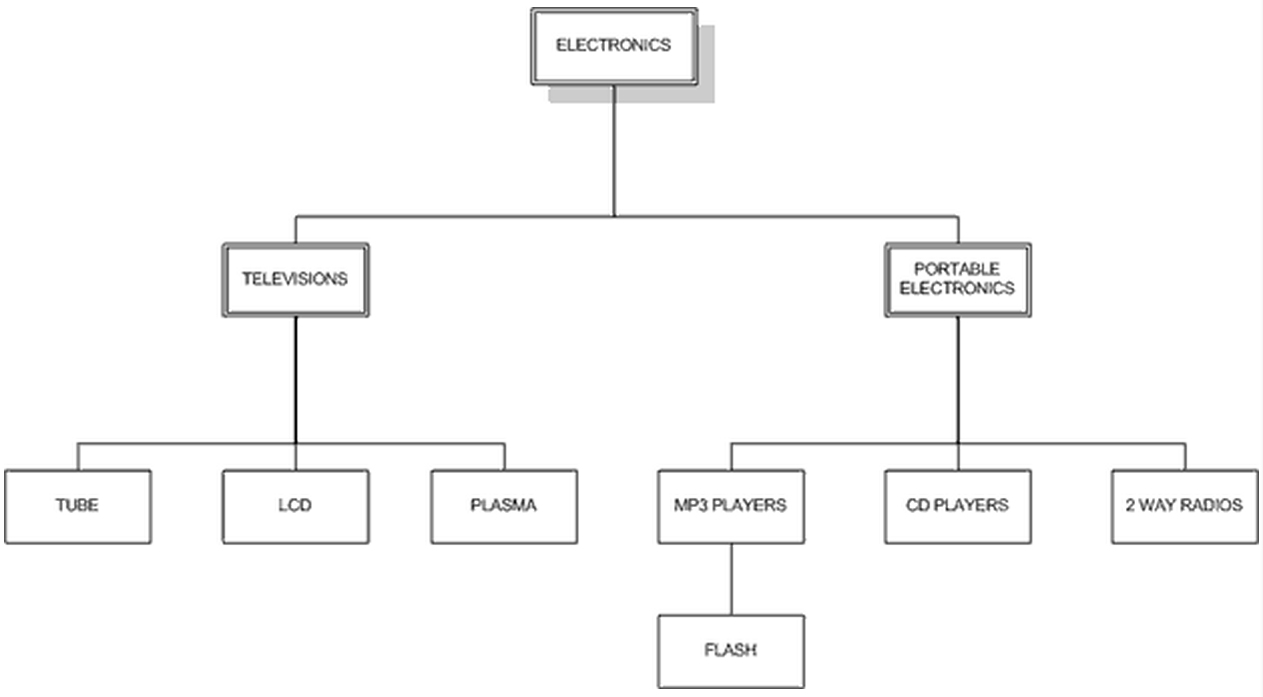 1.文章里介绍了常见的基于parent_id的邻接表模型:
1.文章里介绍了常见的基于parent_id的邻接表模型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
CREATE TABLE category(
category_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(20) NOT NULL,
parent INT DEFAULT NULL
);
+-------------+----------------------+--------+
| category_id | name | parent |
+-------------+----------------------+--------+
| 1 | ELECTRONICS | NULL |
| 2 | TELEVISIONS | 1 |
| 3 | TUBE | 2 |
| 4 | LCD | 2 |
| 5 | PLASMA | 2 |
| 6 | PORTABLE ELECTRONICS | 1 |
| 7 | MP3 PLAYERS | 6 |
| 8 | FLASH | 7 |
| 9 | CD PLAYERS | 6 |
| 10 | 2 WAY RADIOS | 6 |
+-------------+----------------------+--------+
|
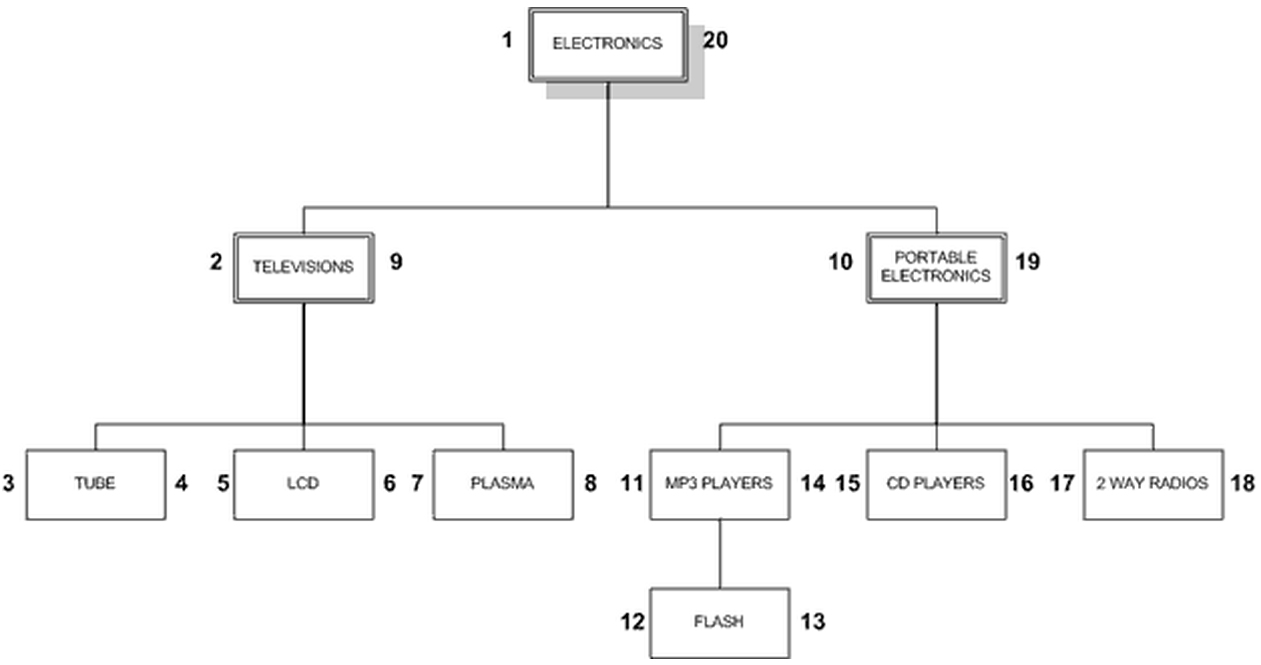
和基于”先序遍历算法”的嵌套集合(Nested Set)模型:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
CREATE TABLE nested_category (
category_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(20) NOT NULL,
lft INT NOT NULL,
rgt INT NOT NULL
);
+-------------+----------------------+-----+-----+
| category_id | name | lft | rgt |
+-------------+----------------------+-----+-----+
| 1 | ELECTRONICS | 1 | 20 |
| 2 | TELEVISIONS | 2 | 9 |
| 3 | TUBE | 3 | 4 |
| 4 | LCD | 5 | 6 |
| 5 | PLASMA | 7 | 8 |
| 6 | PORTABLE ELECTRONICS | 10 | 19 |
| 7 | MP3 PLAYERS | 11 | 14 |
| 8 | FLASH | 12 | 13 |
| 9 | CD PLAYERS | 15 | 16 |
| 10 | 2 WAY RADIOS | 17 | 18 |
+-------------+----------------------+-----+-----+
|
2.分析与点评
上述两种算法我个人觉得各和优点,在页面上的类目,在web网站里,最常见的场景是
1.”检索节点的直接子节点”
2.”检索完整的子树”
场景PK:
1.”检索节点的直接子节点”
就是查找一个目录的直接下级元素,如查询’PORTABLE ELECTRONICS’的直接下级元素:
对于”基于parent_id的邻接表模型”,直接
1
|
SELECT id,name FROM category WHERE parent_id = 6;
|
查找特定parent_id的所有元素就可以了.
对于”嵌套集合(Nested Set)模型”,按原文的方法可复杂了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
SELECT node.name, (COUNT(parent.name) - (sub_tree.depth + 1)) depth
FROM nested_category AS node,
nested_category AS parent,
nested_category AS sub_parent,
(
SELECT node.name, (COUNT(parent.name) - 1) AS depth
FROM nested_category AS node,
nested_category AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
AND node.name = 'PORTABLE ELECTRONICS'
GROUP BY node.name
ORDER BY node.lft
)AS sub_tree
WHERE node.lft BETWEEN parent.lft AND parent.rgt
AND node.lft BETWEEN sub_parent.lft AND sub_parent.rgt
AND sub_parent.name = sub_tree.name
GROUP BY node.name
HAVING depth <= 1
ORDER BY node.lft;
|
这可是最常见的场景,我相信”嵌套集合”这里的性能不会很好,这里”邻接表模型”性能好很多!
2.”检索完整的子树”
如查询以”PORTABLE ELECTRONICS”为根的子树
对于”基于parent_id的邻接表模型”,很复杂,涉及到递归操作,用客户端代码会很复杂,用存储过程还是一样递归搜索,性能实在不行.
对于”嵌套集合(Nested Set)模型”,相当简单:
1
|
SELECT id,name,parent_id FROM category WHERE lft BETWEEN 10 AND 19 ORDER BY lft
|
这里”嵌套集合模型”性能好很多!
3.无限级分类优化
能不能整合”邻接表模型”和”嵌套集合模型”呢?我们试试看
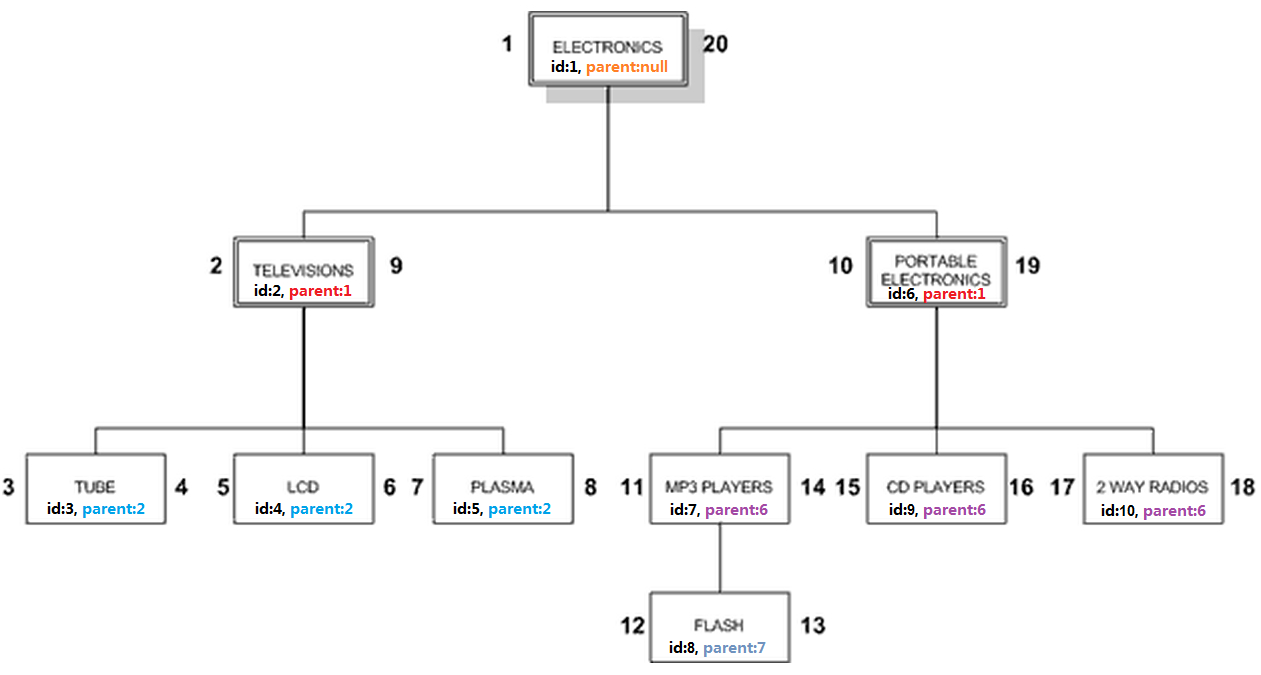
1
2
3
4
5
6
7
|
CREATE TABLE category (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(20) NOT NULL,
lft INT NOT NULL,
rgt INT NOT NULL,
parent_id INT
);
|
表面看上去只是简单的数据整合,实际上述两种模式的功能都整合起来了,
对于1.”检索节点的直接子节点”的场景(利用”邻接表模型”的特性):
1
|
SELECT id,name FROM category WHERE parent_id = 6;
|
对于2.”检索完整的子树”场景(利用”嵌套集合模型”的特性):
1
|
SELECT id,name,parent_id FROM category WHERE lft BETWEEN 10 AND 19;
|
这是”邻接表-嵌套集合-混合模型”,
相对于”嵌套集合模型”,只是简单地增加了”parent_id”字段,就获得了”邻接表模型”的优点,邻接表与嵌套集合的优点整合,非常不错呢。


